跳表与二叉搜索树
Table of Contents
跳表与二叉搜索树
跳表与二叉搜索树
本文探索跳表与二叉搜索树的一些相似之处, 以此来加深对跳表结构的深入理解
适用场景
跳表在Redis中有比较广泛的使用Redis1
技术要点
我们可以认定跳表本质上就是一个平衡二叉搜索树, 跳表的目标是为了能够快速的定位key所在的index
所以可以认定的是跳表的底层数据必定有序
节点内容
我们可以认为跳表的每层节点要保存的数据是
struct node {
key: comparable,
index: usize,
next: node,
next_level_node: node
}
即每一个node的都至少要包含一个用来判断大小的key, 以及一个值记录比自己更大的节点的数量(即下标)
查询
在查询跳表时, 假设有有两个node : now以及next
当查询的值大于 now又小于next时, 会进入now的下一层, 直到next比自己更大或者相等
重复此过程, 如果到达了实际的数据层依然不存在指定数据, 意味着该数据不存在
插入
按照查询流程进行可以得到一条路径
如果不存在插入值, 路径上的所有node 的index都需要加一
如果存在插入值, 返回插入失败
删除
插入流程的反向操作, index - 1
注意要点
跳表在进行插入或者删除操作的时候, 可能会产生类似平衡二叉树的重平衡操作, 这一点需要注意
辨析
为什么使用redis使用跳表而不是二叉搜索树?
因为跳表对于范围区间查询支持更好一些
参考文档
-
Redis
Redis
介绍
问题定位
导致变慢的原因
- Redis全局整理一个大的哈希表, 产生冲突时, 采用的是链式哈希, 换句话说, key对应的是一个哈希桶, 在桶里的寻找是遍历查找.
切片集群2
工具
估算Redis内存: Redis Mem3
问题
如何解决缓存和DB一致性问题?
先更新DB再更新缓存, 还是更新DB后删除缓存, 都有一致性问题
分布式锁保证只有一个线程来做DB-缓存的同步, 其他线程等待结果
在使用分布式锁的时候如果过期了怎么办?
- SETNX or INCR
- LUA脚本
- 要设置一个合理的过期时间, 一般是业务处理p99的2 - 3倍
- 业务处理过程中, 如果有其他的IO操作, 例如读数据库, 调用其他服务等等, 要做好超时处理
- 超时业务在del key前, 验证下是不是自己设的锁
- 后台守护线程, 在业务代码还在运行的时候 定时检查key是不是还存在, 手动实现起来还是比较麻烦的, 一些开源框架, Redisson 可以解决这个问题
案例
分布式锁进阶
Redis 运维工具
https://github.com/oliver006/redis_exporter
https://github.com/sohutv/cachecloud
↩︎
-
切片集群
切片集群
背景
随着单机数据量的增大, RDB 的 bg thread 的 fork 时间会变长, 极大的影响了 redis 服务的可用性, 因此需要有一个水平拓展的方法
在进行持久化的时候, redis 会通过 fork 子进程来完成, fork 的用时操作和 redis 的数据量正相关, 数据越多的时候, 阻塞主线程越久
换句话说, redis 需要一个能够水平扩展的手段, 这种手段应该类似于 MongoDB 的 sharding 和 replicate set 一样, 能够提供好的数据分布, 以及良好的备份.
纵向拓展
增加内存容量, 提高机器性能, 简单直接
随着内存的增加, fork 子进程有可能会阻塞主线程较久的时间
横向拓展
Redis Cluster
Redis 切片集群
一个需求是, 数据切片之后, 在多个实例之间如何分布, 客户端如何知道自己要访问的是哪个一个集群
数据切片和实例的对应关系
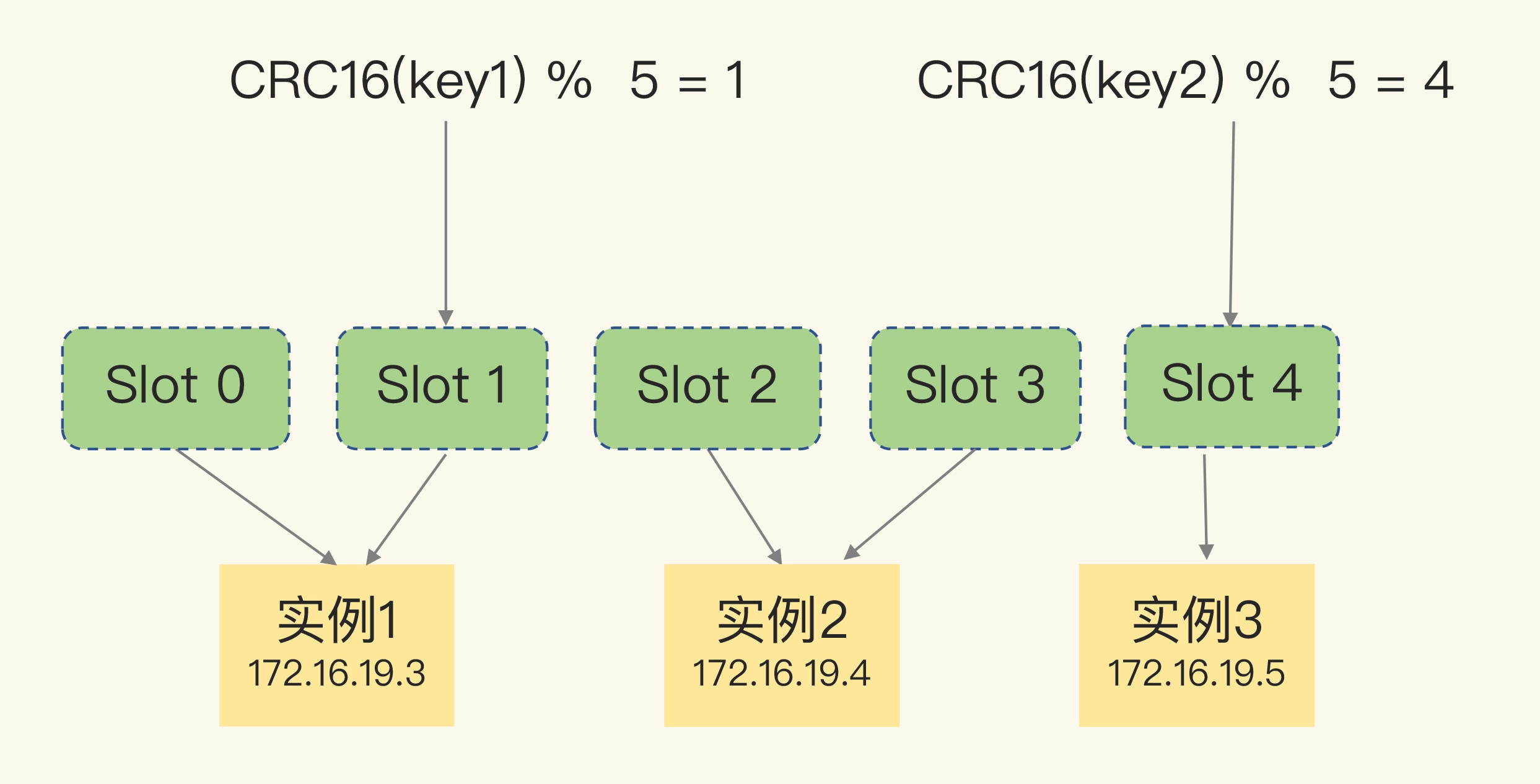
对 key 做 hash, 得到的一个值取模后定位到某个哈希桶里, 哈希桶在 cluster 初始化的时候就确定自己管理哪些[1][注释 1]
客户端访问
在出现以下两种情况时
- 有增减实例, 需要重新分配哈希槽
- 负载均衡, 重新分配哈希槽
Redis Cluster 的重定向机制
客户端向实例发送请求
实例检查后发现已经转移了, 返回 MOVED 命令, 包含了需要请求的实例地址
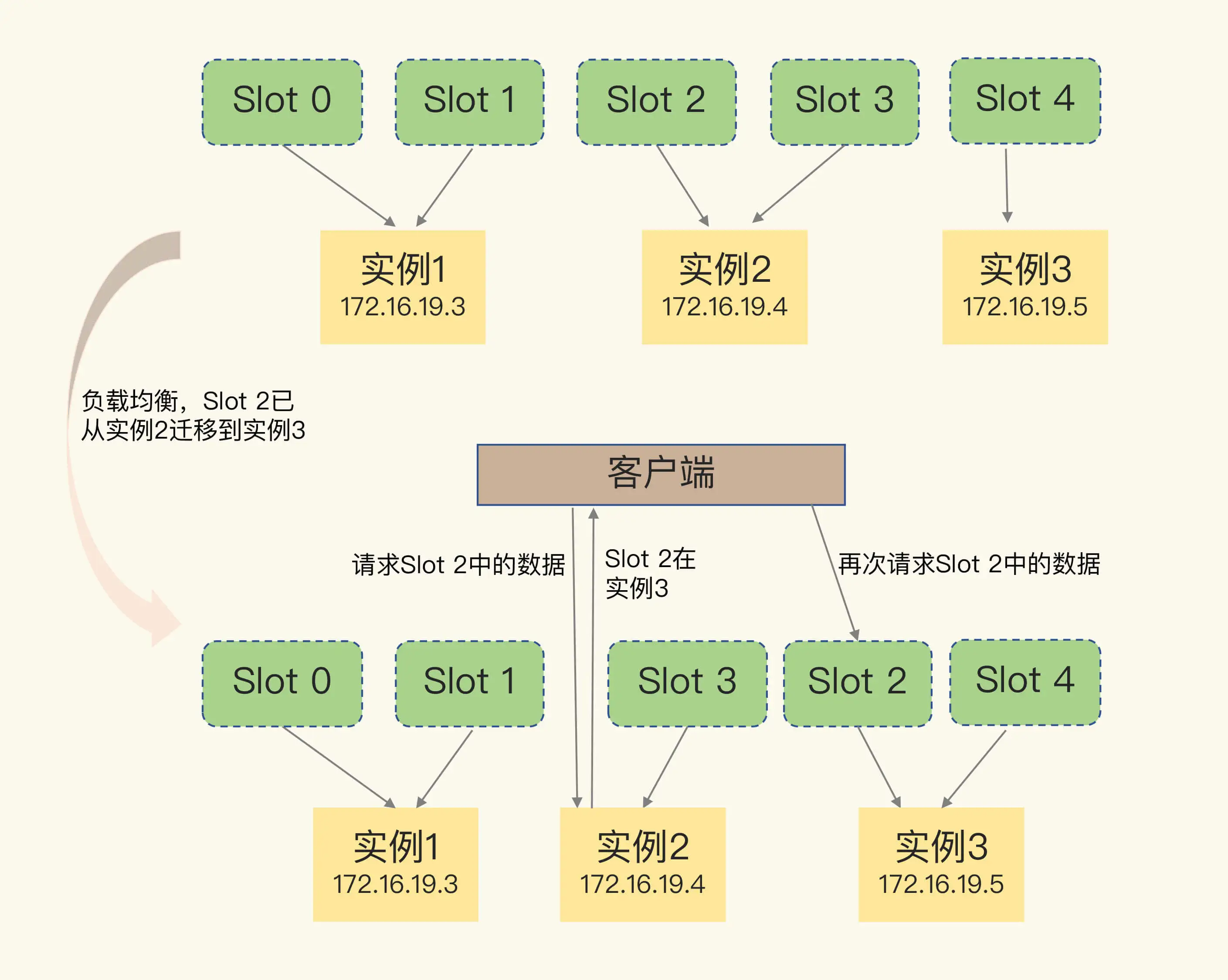
Moved
当产生了哈希槽重分配的情况之后, 客户端没有感知到, 当请求到已经迁移完成的实例的时候, old slots 无法对其回应,同时在集群内部是有
路由
每一个实例都需要保存一份完整的 哈希桶: 实例的表, 方便快速 move ↩︎
-
Redis Mem
Redis Mem